- A+
基本概念
LRU全称Least Recently Used,也就是最近最少使用的意思,是一种内存管理算法,最早应用与Linux操作系统。LRU算法基于一种假设:长期不被使用的数据,在未来被用到的几率也不大,因此,当数据所占内存达到一定阈值时,我们要移除掉最近最少被使用的数据。
算法原理
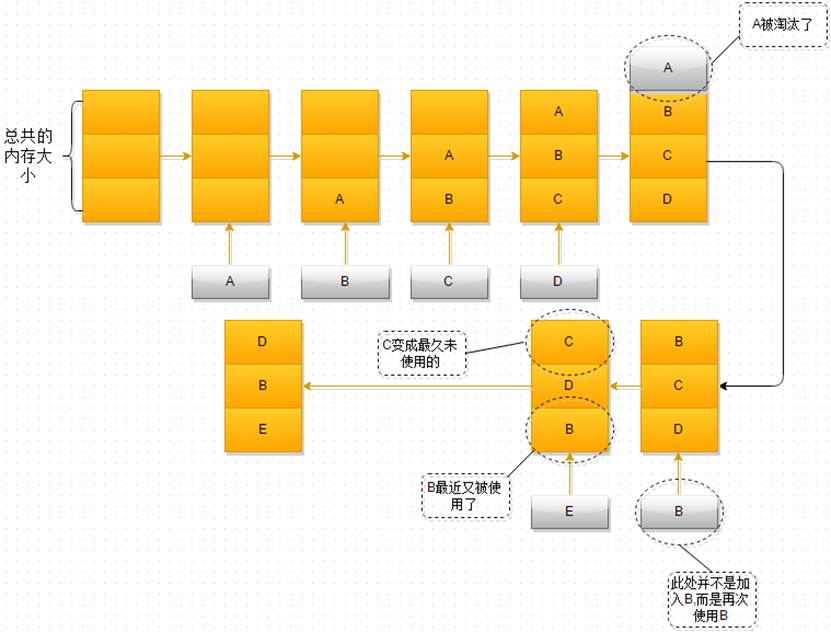
- 最开始时,内存空间是空的,因此依次进入A、B、C是没有问题的
- 当加入D时,就出现了问题,内存空间不够了,因此根据LRU算法,内存空间中A待的时间最为久远,选择A,将其淘汰
- 当再次引用B时,内存空间中的B又处于活跃状态,而C则变成了内存空间中,近段时间最久未使用的
- 当再次向内存空间加入E时,这时内存空间又不足了,选择在内存空间中待的最久的C将其淘汰出内存,这时的内存空间存放的对象就是E->B->D
应用场景
CPU的高速缓存
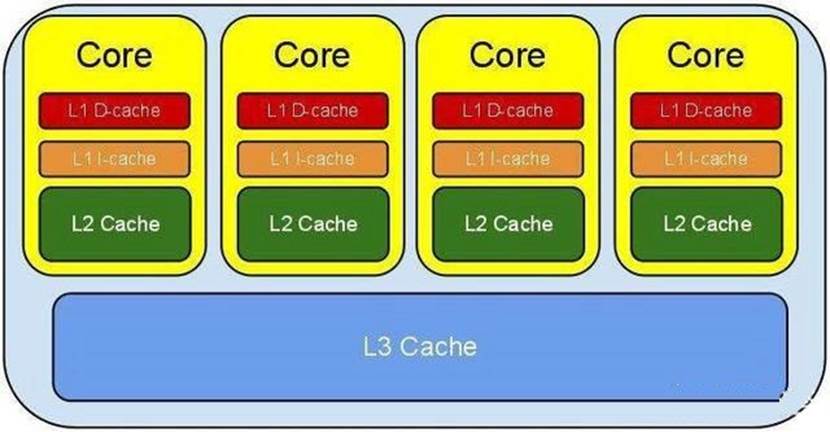
以目前最常见的L1、L2、L3为例:层数越往下,缓存越大,速度也越慢,cpu计算时经常要用到的数据会被从其他地方读到cache里。但cache的大小是有限的。当cpu想要读出一条cache里没有的数据时,势必需要淘汰一些存在cache里的数据来为新的数据腾出位置。这个时候按照什么原则去淘汰呢?一个很自然的想法就是:删掉那些cpu好久没用的数据吧!这就是LRU的策略
Android中显示大量图片
在你应用程序的UI界面加载一张图片是一件很简单的事情,但是当你需要在界面上加载一大堆图片的时候,情况就变得复杂起来。在很多情况下,(比如使用 ListView, GridView 或者 ViewPager 这样的组件),屏幕上显示的图片可以通过滑动屏幕等事件不断地增加,最终导致OOM。为 了保证内存的使用始终维持在一个合理的范围,通常会把被移除屏幕的图片进行回收处理。此时垃圾回收器也会认为你不再持有这些图片的引用,从而对这些图片进 行GC操作。用这种思路来解决问题是非常好的,可是为了能让程序快速运行,在界面上迅速地加载图片,你又必须要考虑到某些图片被回收之后,用户又将它重新滑入屏幕这种情况。这时,你可以使用LRU回收掉长时间不使用的图片,保留最近经常使用的图片,以此来维持图片内存在可控范围内。
技术基础
双向哈希链表与LRU
有一个查询用户信息的场景,用户信息当然是存在数据库里。但是由于我们对用户系统的性能要求比较高,显然不能每一次请求都去查询数据库。所以,我们在内存中创建了一个哈希表作为缓存,每次查找一个用户的时候先在哈希表中查询,以此提高访问性能。

每次查询到的用户信息存入到哈希表中作为缓存,但这样做会存在一个问题:如果用户量很大,那么这个哈希表中的数据就会剧增,导致计算机内存不够用。采用LRU算法可以解决这样的问题。
我们都知道,哈希表是由若干个Key-Value所组成。在“逻辑”上,这些Key-Value是无所谓排列顺序的,谁先谁后都一样。

在哈希链表当中,这些Key-Value不再是彼此无关的存在,而是被一个链条串了起来。每一个Key-Value都具有它的前驱Key-Value、后继Key-Value,就像双向链表中的节点一样。

这样一来,原本无序的哈希表拥有了固定的排列顺序。
1.假设我们使用哈希链表来缓存用户信息,目前缓存了4个用户,这4个用户是按照时间顺序依次从链表右端插入的。
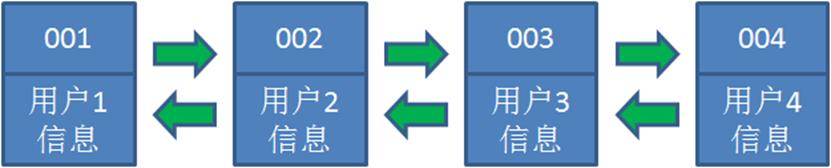
2.此时,业务方访问用户5,由于哈希链表中没有用户5的数据,我们从数据库中读取出来,插入到缓存当中。这时候,链表中最右端是最新访问到的用户5,最左端是最近最少访问的用户1。

3.接下来,业务方访问用户2,哈希链表中存在用户2的数据,我们怎么做呢?我们把用户2从它的前驱节点和后继节点之间移除,重新插入到链表最右端。这时候,链表中最右端变成了最新访问到的用户2,最左端仍然是最近最少访问的用户1。
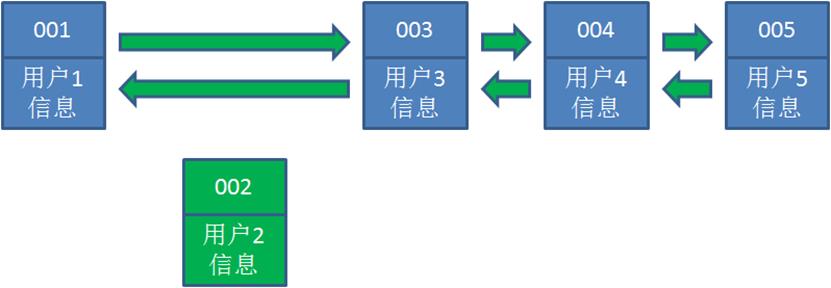

4.接下来,业务方请求修改用户4的信息。同样道理,我们把用户4从原来的位置移动到链表最右侧,并把用户信息的值更新。这时候,链表中最右端是最新访问到的用户4,最左端仍然是最近最少访问的用户1。
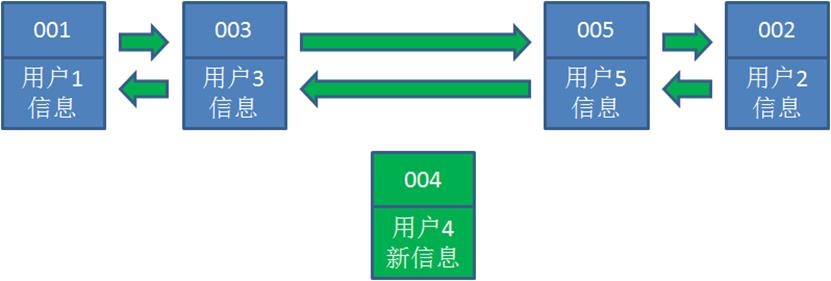

5.后来业务方换口味了,访问用户6,用户6在缓存里没有,需要插入到哈希链表。假设这时候缓存容量已经达到上限,必须先删除最近最少访问的数据,那么位于哈希链表最左端的用户1就会被删除掉,然后再把用户6插入到最右端。


Java中的LinkedHashMap对哈希双向链表做了很好的实现,我们可以直接利用LinkedHashMap做我们自己业务中的LRU算法。
LinkedHashMap原理及与HashMap的区别
在使用HashMap的时候,可能会遇到需要按照当时put的顺序来进行哈希表的遍历。HashMap中不存在保存顺序的机制。在LinkedHashMap中可以保持两种顺序,分别是插入顺序和访问顺序,这个是可以在LinkedHashMap的初始化方法中进行指定的。相对于访问顺序,按照插入顺序进行编排被使用到的场景更多一些,所以默认是按照插入顺序进行编排。如果将构造函数中的accessOrder参数设置为true,即表示按访问顺序排序(也就是LRU了)。LinkedHashMap 继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。

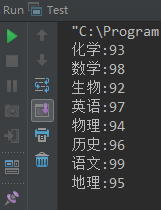
运行结果如下图所示,可以看到,输出的顺序与插入的顺序是一致的。
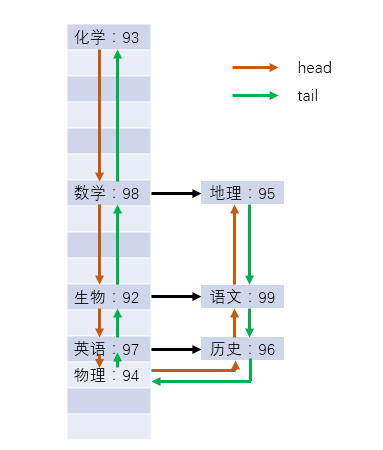
在LinkedHashMap中,是通过双联表的结构来维护节点的顺序的。上文中的程序,实际上在内存中的情况如下图所示,每个节点都进行了双向的连接,维持插入的顺序(默认)。head指向第一个插入的节点,tail指向最后一个节点。
LinkedHashMap是HashMap的亲儿子,直接继承HashMap类。LinkedHashMap中的节点元素为Entry<K,V>,直接继承HashMap.Node<K,V>。UML类图关系如下:
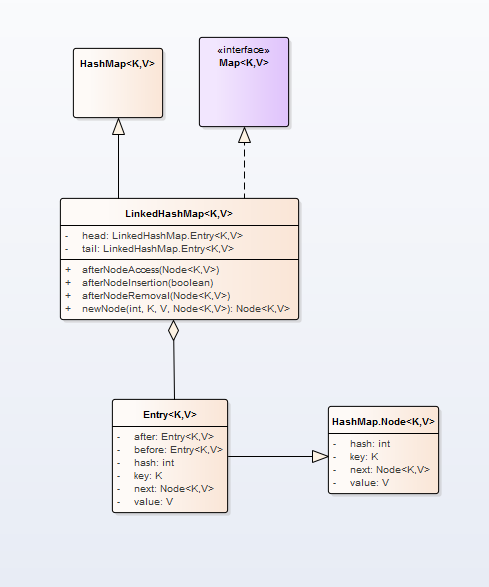
可以看出,LinkedHashMap比HashMap的Entry多出after和before属性,这两属性就是用于标识前后节点的。
实现代码
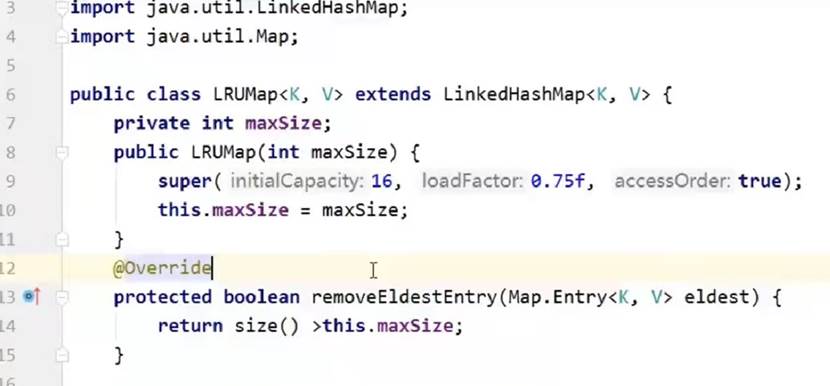
继承Java的LinkedHashMap,设定一个哈希表存储的最大数量maxSize,如果插入元素超过该最大值,则会执行移除不常用元素的操作;重载removeEldestEntry方法,该方法用于判断移除元素的时机。记住,调用父类的构造方法中,将accessOrder参数设置为true,表示考虑按使用先后顺序排序各个元素。